YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone
Edresson Casanova, Julian Weber, Christopher Shulby, Arnaldo Candido Junior, Eren Gölge and Moacir Antonelli Ponti
Abstract:
YourTTS brings the power of a multilingual approach to the task of zero-shot multi-speaker TTS. Our method builds upon the VITS model and adds several novel modifications for zero-shot multi-speaker and multilingual training. We achieved state-of-the-art (SOTA) results in zero-shot multi-speaker TTS and results comparable to SOTA in zero-shot voice conversion on the VCTK dataset. Additionally, our approach achieves promising results in a target language with a single-speaker dataset, opening possibilities for zero-shot multi-speaker TTS and zero-shot voice conversion systems in low-resource languages. Finally, it is possible to fine-tune the YourTTS model with less than 1 minute of speech and achieve state-of-the-art results in voice similarity and with reasonable quality. This is important to allow synthesis for speakers with a very different voice or recording characteristics from those seen during training.
System architecture:
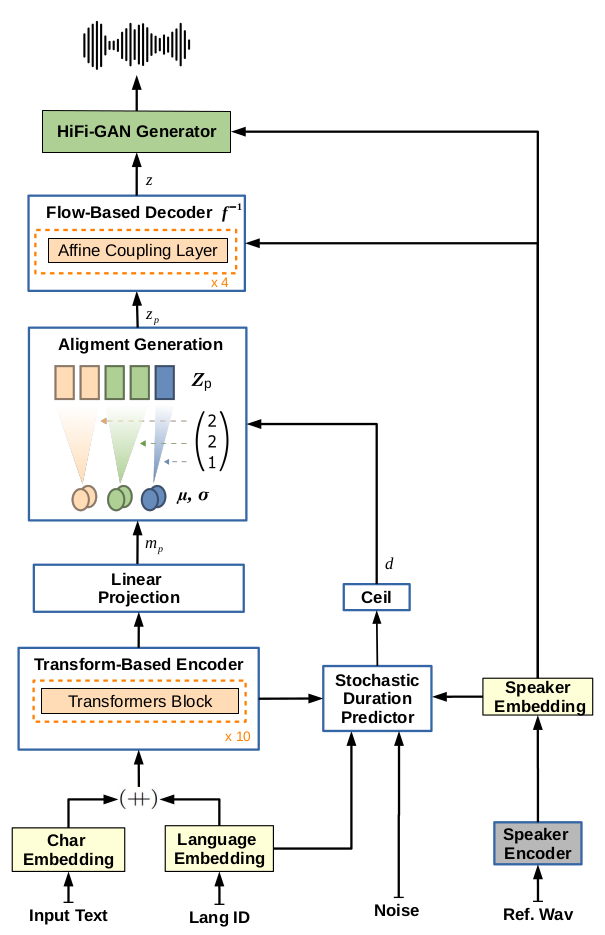
Zero-shot Multi-Speaker TTS
Audio Samples for VCTK test speakers
| Model | Unseen Speakers (test) | |||||||||||
| p225 | p234 | p238 | p245 | p248 | p261 | p294 | p302 | p326 | p335 | p347 | ||
| Emb reference | ||||||||||||
| Exp.1 | ||||||||||||
| Exp.1 + SCL | ||||||||||||
| Exp.2 | ||||||||||||
| Exp.2 + SCL | ||||||||||||
| Exp.3 | ||||||||||||
| Exp.3 + SCL | ||||||||||||
| Exp.4 + SCL | ||||||||||||
Audio Samples for LibriTTS test speakers
| Model | Unseen Speakers (test) | |||||||||||
| 1089 | 1188 | 121 | 1284 | 1580 | 1995 | 2300 | 237 | 260 | 908 | |||
| Emb reference | ||||||||||||
| Ground truth | ||||||||||||
| Exp.1 | ||||||||||||
| Exp.1 + SCL | ||||||||||||
| Exp.2 | ||||||||||||
| Exp.2 + SCL | ||||||||||||
| Exp.3 | ||||||||||||
| Exp.3 + SCL | ||||||||||||
| Exp.4 + SCL | ||||||||||||
Audio Samples for MLS Portuguese test speakers
| Model | Unseen Speakers (test) | |||||||||||
| 11995 | 12249 | 12287 | 12710 | 13069 | 3050 | 4367 | 5677 | 7925 | 9351 | |||
| Emb reference | ||||||||||||
| Exp.2 | ||||||||||||
| Exp.2 + SCL | ||||||||||||
| Exp.3 | ||||||||||||
| Exp.3 + SCL | ||||||||||||
| Exp.4 + SCL | ||||||||||||
Speaker Adaptation
Exp.4 + SCL| Mode | Unseen Common Voice Speakers | ||||
| English Male | English Female | Portuguese Male | Portuguese Female | ||
| Ground Truth | |||||
| Zero-shot | |||||
| Fine-Tuned | |||||
Zero-Shot Voice Conversion
Exp.4 + SCLEach row of the table shows the voice of the speaker of the current row generated through a reference of the speaker present in the column. Therefore, all samples of a row should sound similar.
English speakers to English Speakers
Female to Female
| Model | Unseen Speakers (test) | |||||
| Emb Ref. | p261 | p225 | p294 | p335 | ||
| p261 | ||||||
| p225 | ||||||
| p294 | ||||||
| p335 | ||||||
Male to Male
| Model | Unseen Speakers (test) | |||||
| Emb Ref. | p245 | p302 | p326 | p347 | ||
| p245 | ||||||
| p302 | ||||||
| p326 | ||||||
| p347 | ||||||
Female to Male
| Model | Unseen Speakers (test) | |||||
| Emb Ref. | p225 | p261 | p294 | p335 | ||
| p245 | ||||||
| p302 | ||||||
| p326 | ||||||
| p347 | ||||||
Male to Female
| Model | Unseen Speakers (test) | |||||
| Emb Ref. | p245 | p302 | p326 | p347 | ||
| p225 | ||||||
| p261 | ||||||
| p294 | ||||||
| p335 | ||||||
Portuguese Speakers to Portuguese Speakers
Female to Female
| Model | Unseen Speakers (test) | |||||
| Emb Ref. | 11995 | 13069 | 3050 | 7925 | ||
| 11995 | ||||||
| 13069 | ||||||
| 3050 | ||||||
| 7925 | ||||||
Male to Male
| Model | Unseen Speakers (test) | |||||
| Emb Ref. | 12287 | 4367 | 5677 | 9351 | ||
| 12287 | ||||||
| 4367 | ||||||
| 5677 | ||||||
| 9351 | ||||||
Female to Male
| Model | Unseen Speakers (test) | |||||
| Emb Ref. | 11995 | 13069 | 3050 | 7925 | ||
| 12287 | ||||||
| 4367 | ||||||
| 5677 | ||||||
| 9351 | ||||||
Male to Female
| Model | Unseen Speakers (test) | |||||
| Emb Ref. | 12287 | 4367 | 5677 | 9351 | ||
| 11995 | ||||||
| 13069 | ||||||
| 3050 | ||||||
| 7925 | ||||||
English Speakers to Portuguese Speakers
Female to Female
| Model | Unseen Speakers (test) | |||||
| Emb Ref. | p225 | p261 | p294 | p335 | ||
| 11995 | ||||||
| 13069 | ||||||
| 3050 | ||||||
| 7925 | ||||||
Male to Male
| Model | Unseen Speakers (test) | |||||
| Emb Ref. | p245 | p302 | p326 | p347 | ||
| 12287 | ||||||
| 4367 | ||||||
| 5677 | ||||||
| 9351 | ||||||
Female to Male
| Model | Unseen Speakers (test) | |||||
| Emb Ref. | p225 | p261 | p294 | p335 | ||
| 12287 | ||||||
| 4367 | ||||||
| 5677 | ||||||
| 9351 | ||||||
Male to Female
| Model | Unseen Speakers (test) | |||||
| Emb Ref. | p245 | p302 | p326 | p347 | ||
| 11995 | ||||||
| 13069 | ||||||
| 3050 | ||||||
| 7925 | ||||||
Portuguese Speakers to English Speakers
Female to Female
| Model | Unseen Speakers (test) | |||||
| Emb Ref. | 11995 | 13069 | 3050 | 7925 | ||
| p225 | ||||||
| p261 | ||||||
| p294 | ||||||
| p335 | ||||||
Male to Male
| Model | Unseen Speakers (test) | |||||
| Emb Ref. | 12287 | 4367 | 5677 | 9351 | ||
| p245 | ||||||
| p302 | ||||||
| p326 | ||||||
| p347 | ||||||
Female to Male
| Model | Unseen Speakers (test) | |||||
| Emb Ref. | 11995 | 13069 | 3050 | 7925 | ||
| p245 | ||||||
| p302 | ||||||
| p326 | ||||||
| p347 | ||||||
Male to Female
| Model | Unseen Speakers (test) | |||||
| Emb Ref. | 12287 | 4367 | 5677 | 9351 | ||
| p225 | ||||||
| p261 | ||||||
| p294 | ||||||
| p335 | ||||||
Citation
@ARTICLE{2021arXiv211202418C,
author = {{Casanova}, Edresson and {Weber}, Julian and {Shulby}, Christopher and {Junior}, Arnaldo Candido and {G{\"o}lge}, Eren and {Antonelli Ponti}, Moacir},
title = "{YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone}",
journal = {arXiv e-prints},
keywords = {Computer Science - Sound, Computer Science - Computation and Language, Electrical Engineering and Systems Science - Audio and Speech Processing},
year = 2021,
month = dec,
eid = {arXiv:2112.02418},
pages = {arXiv:2112.02418},
archivePrefix = {arXiv},
eprint = {2112.02418},
primaryClass = {cs.SD},
adsurl = {https://ui.adsabs.harvard.edu/abs/2021arXiv211202418C},
adsnote = {Provided by the SAO/NASA Astrophysics Data System}
}