Pytorch unofficial implementation of VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking
Paper: arXiv
Authors: Quan Wang *, Hannah Muckenhirn *, Kevin Wilson, Prashant Sridhar, Zelin Wu, John Hershey, Rif A. Saurous, Ron J. Weiss, Ye Jia, Ignacio Lopez Moreno. (*: Equal contribution.)
Abstract: In this paper, we present a novel system that separates the voice of a target speaker from multi-speaker signals, by making use of a reference signal from the target speaker. We achieve this by training two separate neural networks: (1) A speaker recognition network that produces speaker-discriminative embeddings; (2) A spectrogram masking network that takes both noisy spectrogram and speaker embedding as input, and produces a mask. Our system significantly reduces the speech recognition WER on multi-speaker signals, with minimal WER degradation on single-speaker signals.
System architecture:
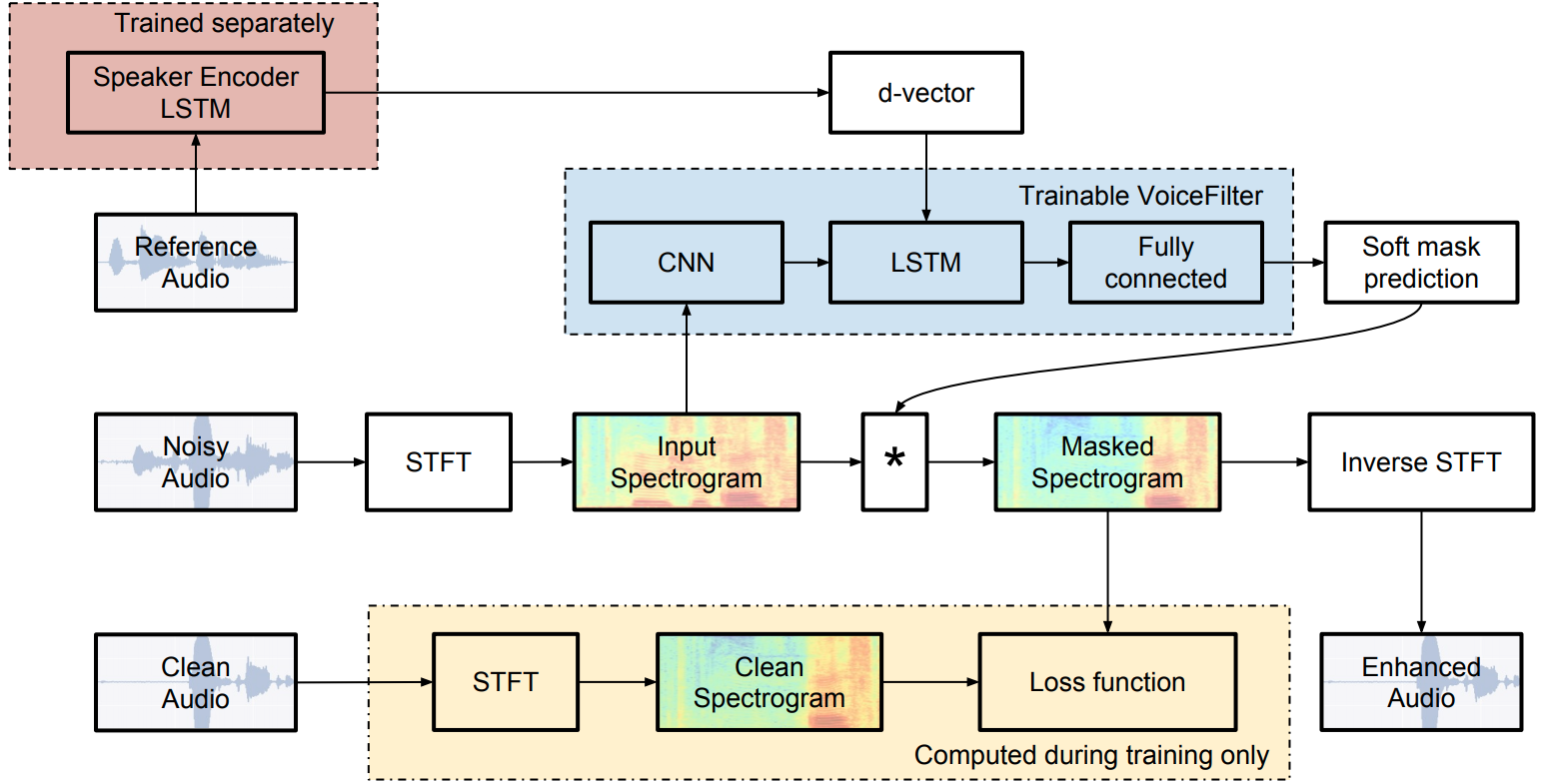
Citation:
@inproceedings{Wang2019,
author={Quan Wang and Hannah Muckenhirn and Kevin Wilson and Prashant Sridhar and Zelin Wu and John R. Hershey and
Rif A. Saurous and Ron J. Weiss and Ye Jia and Ignacio Lopez Moreno},
title={{VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking}},
year=2019,
booktitle={Proc. Interspeech 2019},
pages={2728--2732},
doi={10.21437/Interspeech.2019-1101},
url={http://dx.doi.org/10.21437/Interspeech.2019-1101}
}
Improvements
- We use Si-SNR with PIT instead of Power Law compressed loss, because it allows us to achieve a better result ( comparison available in: https://github.com/Edresson/VoiceSplit).
- We used the MISH activation function instead of ReLU and this has improved the result
Random audio samples from LibriSpeech testing set
VoiceFilter model: CNN + bi-LSTM + fully connected + Si-SNR with PIT loss
Apply VoiceFilter on noisy audio (2 speakers)
Meaning of the columns in the table below:
- The noisy audio input to the VoiceFilter. It's generated by summing the clean audio with an interference audio from another speaker.
- The output from the VoiceFilter.
- The reference audio from which we extract the d-vector. The d-vector is another input to the VoiceFilter. This audio comes from the same speaker as the clean audio.
- The clean audio, which is the ground truth.
| Noisy audio input | Enhanced audio output | Reference audio for d-vector | Clean audio (ground truth) |
|---|---|---|---|
Apply VoiceFilter on clean audio (single speaker)
Meaning of the columns in the table below:
- The clean audio, which we feed as the input to the VoiceFilter.
- The output from the VoiceFilter.
- The reference audio from which we extract the d-vector. The d-vector is another input to the VoiceFilter. This audio comes from the same speaker as the clean audio.
| Clean audio input | Enhanced audio output | Reference audio for d-vector |
|---|---|---|
FAQ
Dataset information
For training and evaluating our VoiceFilter models, we had been using the LibriSpeech dataset.
Here we provide the division of training-vs-testing as CSV files. Each line of the CSV files is a tuple of three utterance IDs:
(clean utterance, utterance for computing d-vector, interference utterance)